Speech-based Classification
Machine Learning
Abstract
As the amount of robots that are deployed into social settings increases, the amount of expected interactions between robots and humans increases as well. However, these interactions can be difficult because robots lack the innate features and characteristics that humans have become accustomed to reading in social situations. Past works have attempted to bridge this gap by exploring the addition of an expressive feature such as robot gaze, responsive emotional expressions, or other modalities of expression to robots that are expected to interact frequently with humans. However, uni-modal expression often does not fully capture the complexities of social interaction. In this work we implement a reinforcement learning based control algorithm to control both a robot’s eye gaze as well as the robot’s emotional response while the robot is interacting with one or more humans.
Github Link: https://github.com/nwaggu/learning-based-control-gaze
Technical Contribution
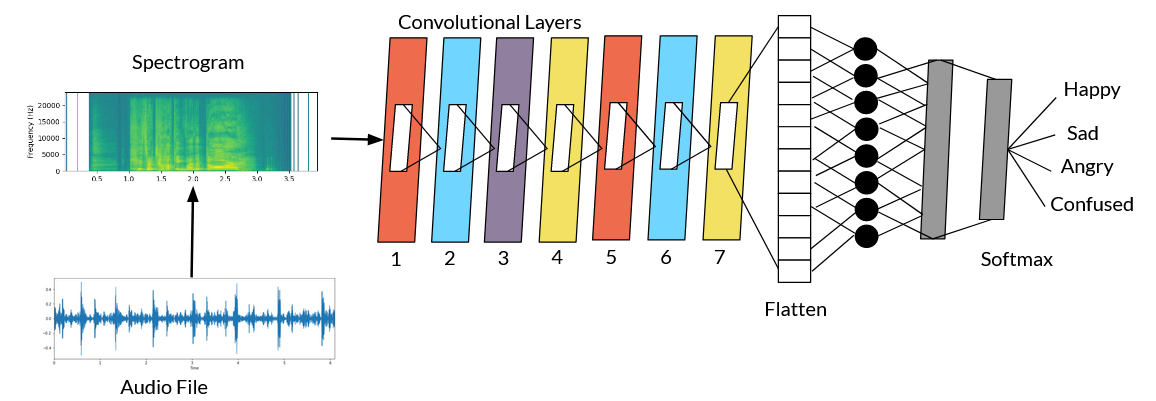
My main contribution to the presented work was the design of a speech to emotion convolutional neural network that was meant to decide the final expression of the robotic eyes. The network itself was designed in Pytorch and took as input a spectrogram representation of the audio. We utilized a Deep Stride 2-D convolutional neural network (CNN) referenced in previous work [1] in order to classify 4 emotion. The CNN had seven convolutional blocks, a flatten layer, two fully connected layers, and a softmax function. The first convolutional layer had 16 out channels, a kernel size of 7x7, a stride of 2x2, and a padding of 2x2. The second convolutional layer had 32 out channels, a kernel size of 5x5, and a stride of 2x2. The third convolutional layer had 32 out channels, a kernel size of 3x3, and a stride of 2x2. The fourth and fifth convolutional layer were identical and had 64 out channels, a kernel size of 3x3, and a stride of 2x2. The sixth and seventh layers had 128 out channels and the same stride and padding as the fourth and fifth layers. The first linear layer had a dimension of 1664x512 and the second linear layer had a dimension of 514x4 before being passed to the softmax layer. The architecture and workflow can be seen in the figure below.
References
[1] Mustaqeem and S. Kwon, “A cnn-assisted enhanced audio signal processing for speech emotion recogni- tion,” Sensors, vol. 20, no. 1, p. 183, Dec. 2019, ISSN: 1424-8220.
Methods
- Convolutional Neural Network
Tools
- Python
- Pytorch
Samples